


In the modern corporate landscape, Environmental, Social, and Governance (ESG) has become a benchmark for corporate accountability. Institutional investors and rating agencies scrutinize these reports to inform capital allocation of decisions. For investors and boards, these documents are vital. Analysts, however, find them high friction.
ESG reports are dense, hundreds of pages long, filled with domain-specific jargon, and lack a standardized structure. Extracting specific data points is a tedious, manual process.

At Codya, we found that generic AI models tend to hallucinate when asked about specific details in lengthy regulatory documents. They also cannot provide verifiable source citations, which is a requirement in professional ESG analysis. That is why we built the ESG Assistant: a specialized ESG chatbot designed to deliver valuable insights using RAG architecture.
Here’s a look at how we built it, our tech stack, and the lessons we learned.
The Problem
The analysis of non-financial ESG reports is a rapidly growing discipline, but it faces significant challenges. For investors who increasingly integrate ESG factors into allocation decisions, this complexity creates friction: while the information exists, efficiently accessing and comparing it across companies remains difficult.
The traditional approach involves teams of analysts manually combing through PDFs. The alternative - using general-purpose AI models - often leads to incorrect outputs.
In our internal tests, when we asked a general AI model about specific actions Bayer took regarding supplier verification in 2023, the model provided imprecise, generic, or incorrect answers, often hallucinating facts with no basis in the actual report. For example, it cited complaints to the OECD that were not in the report, and it gave generic definitions of risk management rather than specific audit numbers.
Our Goal: Build an ESG Assistant that uses RAG in practice to deliver:
- Minimized hallucinations: answers must be grounded in the provided documents.
- Source Citations: Every claim must link back to a specific page and chapter.
- Multilingualism: Handling of German and English reports.
- Comparative Analysis: The ability to compare data across years (2023 vs. 2024) or between different companies.
- Contextual Conversation: The ability to maintain a continuous dialogue, remembering previous interactions to handle follow-up questions naturally.
Tech Stack
To ensure we meet the project's requirements, we dedicated a full sprint to research and technology stack selection. Here is what we chose and why:
Cloud Provider: Microsoft Azure
Our choice was driven primarily by the Azure OpenAI Service. Our internal evaluation showed that the GPT family of models performed best in our benchmarks for analyzing complex ESG reports. Azure is the cloud provider that allows us to use these models within a secure, enterprise-grade PaaS environment. On the other hand, since our team utilizes Azure DevOps for our development lifecycle, sticking to the Microsoft ecosystem significantly streamlined our integration and CI/CD pipelines.
Orchestration: LangChain + LangGraph
We chose those technologies to give the AI the ability to "remember" context across a long conversation and handle complex, multi-step tasks - much like a human analyst would. It also provides an easy way to switch between AI models as technology evolves, without rewriting the entire application. Additionally, it allows us to build "self-correcting" workflows, where the AI can verify its own answers before presenting them to the user, thereby improving reliability.
LLM: GPT-4.1-mini
We selected GPT-4.1-mini as our strategic starting point. With a cost of just $0.60 per million tokens and excellent German language support, it allows us to run extensive retrieval optimization tests without incurring high costs. This model offers the balance of speed and reasoning capability to benchmark our system before considering more expensive models.
Vector Database: Qdrant
Qdrant is a widely adopted, industry-proven solution with a dynamic community, which guarantees long-term support and reliability. Unlike some enterprise tools with complex feature sets, Qdrant is streamlined and focused.
Embedding Model: mixedbread-ai/deepset-mxbai-embed-de-large-v1
Our analysis focuses on DAX index companies, handling both German and English documents. We chose this model because it is specifically fine-tuned for this bilingual context and supports binary quantization for efficient storage. While we considered newer alternatives like BAAI/bge-m3, this model offered the best balance of targeted performance and compatibility with our development infrastructure.
Document Processing: PyMuPDF
PDF reports are often visually complex, containing columns, tables, and mixed media. PyMuPDF provides the fast, reliable extraction of text and metadata we need to create clean "chunks" for our vector database, outperforming other libraries in both speed and accuracy.
Guardrails: Guardrails AI
We implemented Guardrails AI to act as a "quality assurance" layer between the user and the model. It is a strict filter for both inputs and outputs, ensuring the model stays grounded in the provided data and preventing the generation of toxic, irrelevant, or hallucinated content.
Frontend: React + Assistant UI
We chose React because it is the industry standard for building modern web applications. On the other hand, Assistant UI enabled us to quickly build a chat-optimized interface that supports advanced features like streaming responses and citation rendering.
Backend: Python + FastAPI
FastAPI serves as the high-performance backbone of our application. Its asynchronous nature allows it to handle multiple concurrent user requests efficiently, while its native Python integration ensures seamless communication with our AI logic and RAG pipeline.
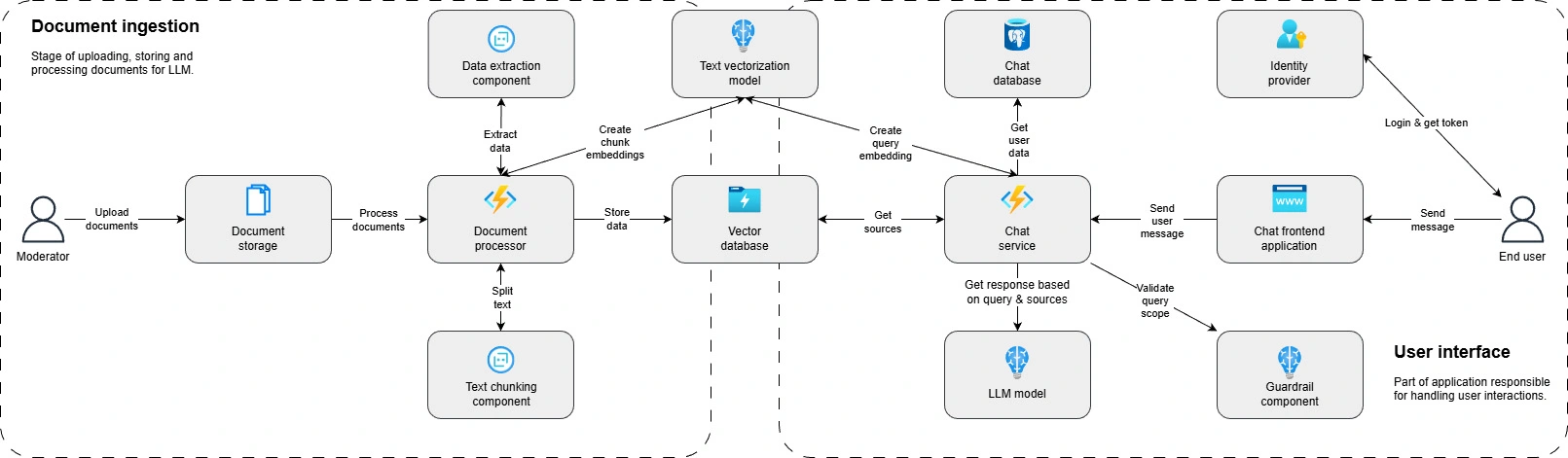
The Architecture
The ESG Assistant is a classic implementation of Retrieval-Augmented Generation, but with several custom layers to handle the nuance of financial documents.
The Data Pipeline:
- Ingestion: We ingest PDF reports. The text is extracted and cleaned.
- Processing: PyMuPDF extracts text and metadata.
- Chunking: The text is split into semantic chunks. We had to develop a strategy that preserves the context of "Page Number" and "Chapter Name" for every single chunk to enable accurate citations.
- Embedding: The processed text chunks are passed through the mixedbread-ai model, converting them into vector representations.
- Persistence: These vectors are indexed in the Qdrant database alongside their metadata (page numbers, chapters).
The Inference Flow:
- User Query: "How does Bayer verify its suppliers in 2023?"
- Guardrails: The system checks if the question is relevant to ESG.
- Embedding: The system converts the question into a vector.
- Retrieval: The system searches Qdrant for the most similar vectors.
- Generation: The LLM receives the chunks as context and generates an answer, strictly conditioned to cite the sources provided.
- Output: The user sees the answer with citations (e.g., "Chapter 4.3, Page 99").
This architecture ensures the assistant provides precise, documented answers, making it easy to quickly navigate the presented facts.
Technical Deep Dive
ESG reports are not simple text files. They are visually rich in PDFs containing multi-column layouts, floating diagrams, sidebars, and tables.
The Challenge: "Where did you get that?"
We promised users source citations - indicating the specific page and chapter for every piece of information generated. However, simply feeding text to an LLM often causes the model to lose track of which sentence came from which page chunk.
The Solution: Metadata-Aware Context Injection
We couldn't rely on the LLM to "remember" page numbers from raw text. We had to engineer the prompt to be metadata aware.
- Smart Chunking: We utilized PyMuPDF to map text blocks. Instead of arbitrary character limits, we tried to respect paragraph boundaries.
- Context Construction: When constructing the prompt for the LLM, we formatted the context blocks like this:
- [Source ID: 123, Page: 99, Chapter: 4.3] Text content...
- Strict Instruction: The system prompt required the LLM to reference the [Source ID] in its final output.
- Post-Processing: The application parses these IDs in the response and converts them into user-friendly citations (e.g., "chapter 4.3 Sustainability in the Supply Chain, page 99").
This allowed us to achieve the level of granularity where the bot could explicitly state: "Bayer verifies its suppliers using online assessments... (Page 99)", whereas a generic model would just offer a vague summary.
Project Timeline
The project was delivered in 8 weeks, divided into four distinct phases:
Week 1: Architecture Design
We defined the high-level system architecture, identified key components, and established integration points. This phase resulted in a technical design document that guided all subsequent work.
Weeks 2–3: Technology Research & Prototyping
The team evaluated candidate technologies for each component. We built throwaway prototypes to validate our assumptions about the RAG pipeline.
Weeks 4–6: Core Development
With the tech stack locked, we moved into implementation. This phase covered the full data pipeline (ingestion, chunking, embedding), the inference flow, guardrails integration, and the frontend chat interface. We worked in weekly sprints with deployable increments.
Weeks 7–8: Testing & Improvements
The final phase focused on end-to-end testing and performance optimization.
Conclusions and Lessons Learned
No project is truly complete without a look back. We make it a standard practice to wrap up our work with a deep-dive retrospective to identify what went well and what we can do better.
Key Challenges Faced
- Data Heterogeneity: There is no standard format for the DAX index reports. Some use tables for emissions data; others use bar charts. Extracting answers from complex tables and diagrams remains a significant challenge for text-based RAG.
- Hallucination vs. Strictness: If the assistant cannot answer a question based on the report, it must inform the user rather than guessing.
- Latency: The "First Query Performance" was a critical KPI. Initial cold starts of the application (container spin-up) and time-to-first token in streaming responses were major optimization targets.
What We Would Do Differently
- Evaluation First, Not Last: We lost time by verifying answers "by eye." In hindsight, we should have set up Ragas and Langfuse evaluation pipelines immediately. We needed a "Golden Dataset" of questions and answers (QA pairs) to run automated regression tests every time we tweaked the chunking strategy.
- Chunking Strategy is the Key: We underestimated the complexity of chunking. We missed specific tests for how our chunking logic handled page breaks and mid-sentence splits. Better semantic chunking strategies (perhaps agentic chunking) could further improve retrieval accuracy.
- DevOps & Infrastructure: Optimization of the Docker container start-up time was left too late in the process. This slowed down the debugging cycle.
What Went Well
- Deployment: The application was successfully deployed to Azure with a web-based interface that requires no installation and can be embedded on any website.
- Guardrails: The implementation of strict boundaries worked. The bot effectively blocks non-ESG questions, maintaining its role as a specialized tool.
- User Flow: The onboarding flow - email verification and simple chat interface - proved intuitive for internal users.
Summary
The ESG Assistant project demonstrates that RAG architecture can be a viable approach for professional, high-stakes document analysis.
Technical Execution
- 1 Dedicated Team delivering the entire project lifecycle, from architectural research to deployment.
- 2 Months total time-to-market, transforming the initial concept into a live, production-ready application.
- 960 Working Hours invested in deep-dive research, iterative development, and comprehensive testing to ensure a high-quality release.
The Results
- 80+ Complex Reports successfully processed and indexed.
- 5-Second Average Response Time for fully cited, analytical answers.
- Significantly, Greater Accuracy compared to standard, non-RAG LLMs.
- Traceability: Every answer is backed by a specific page number, chapter, and citation.
By moving away from generic models and building a specialized, citation-backed system, we transformed a process that used to take hours of manual reading into a conversation that takes minutes. The assistant allows users to show changes between years, verify supplier audits, and access precise data without noise.




