


Traditional AI systems often treated vision and language as separate domains: computer vision could analyze images, while language models could generate text. For businesses, this frequently meant maintaining separate components, building integrations between them, and accepting limitations in end-to-end capabilities.
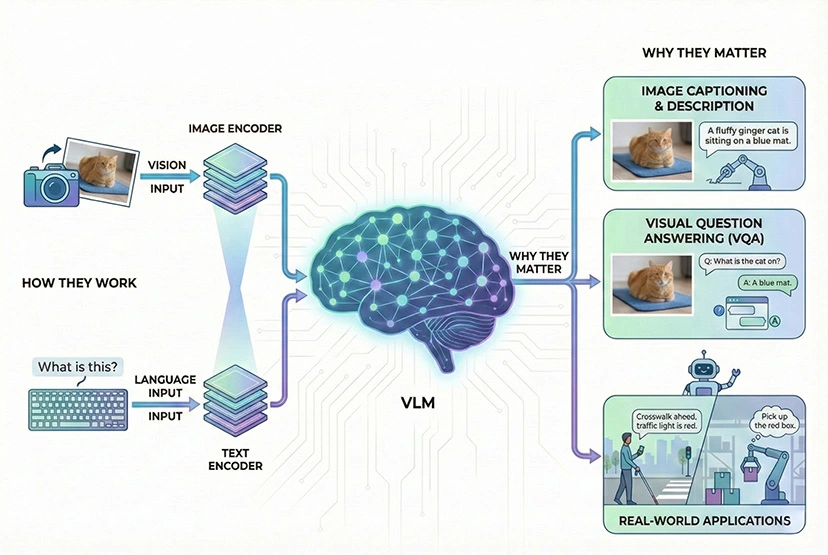
Vision Language Models address this by combining image understanding with language processing within one multimodal system. Instead of using two separate models to analyze an image and then describe it, VLMs handle both tasks seamlessly, accelerating time-to-market and enabling advanced multimodal applications.
Computer Vision vs. Language Models
To understand the significance of VLMs, it helps to distinguish the two domains they connect: computer vision and natural language processing.
Computer Vision: The Eyes of AI
Computer Vision (CV) focuses on enabling machines to interpret visual data such as images and videos. Common goals include detecting objects, recognizing patterns, and extracting structured information from pixels.
Language Models: The Voice of AI
Large Language Models (LLMs) are AI systems designed to process and generate text. They learn statistical patterns in language and can produce coherent responses based on textual input.
Bridging the Gap: What is a Vision Language Model?
Vision Language Models combine computer vision and natural language processing to connect visual content with language. Depending on the architecture, they can take images and text as input and produce text output or produce shared embeddings for retrieval tasks.
The table below highlights common differences between a traditional LLM and a VLM.
https://opencv.org/blog/vision-language-models/
How VLMs Work: A Look Inside
While details differ across model families, many modern VLMs include three building blocks:
Image Encoder
This component processes the visual data. While earlier versions of VLMs used deep learning algorithms like convolutional neural networks (CNNs), modern models primarily use a Vision Transformer (ViT). A ViT breaks an image into smaller patches and extracts meaningful visual features like colors, shapes, and textures. Crucially, these ViTs are pre-trained on large-scale image datasets, ensuring they can effectively capture the visual features necessary for complex multimodal tasks.
Vision–language connector (projector or attention mechanism)
To connect vision features with a language model, some generative VLMs use a projection layer that maps visual features into the language model’s token/embedding space (often described as “visual tokens”). Other designs integrate vision features via cross-attention, or use dual-encoder setups for retrieval rather than generation.
Large Language Model
Instead of a simple text encoder, modern VLMs utilize a full, pre-trained Large Language Model as their core reasoning engine. This LLM acts as a decoder. It takes the sequence of "visual tokens" provided by the bridge, combines them with the user’s text prompt, and processes everything together. By performing next-token prediction, the LLM generates a coherent text response, based on both visual and textual inputs.
What Can VLMs Do? Real-World Applications
By merging visual perception with linguistic comprehension, VLMs have opened the door to a wide range of applications that were previously difficult to achieve with separate AI systems.
Image Captioning: VLMs can automatically generate accurate captions for images. This is invaluable for accessibility, such as providing descriptions for screen readers used by the visually impaired.
Visual Question Answering (VQA): This is the ability to ask specific questions about an image and receive detailed, context-aware answers.
Image-Text Retrieval: Instead of using only text, a user can search with both an image and a text query to find what they are looking for.
Visual Reasoning & Analysis: Beyond simple descriptions, VLMs can analyze charts, read handwriting (OCR), solve math problems shown in images, or analyze UI screenshots to generate code.
The VLM Landscape: A Comparison of Key Models
The field of VLMs is advancing rapidly, with several powerful and distinct models available for researchers and developers. Here is a look at some of the key players in the VLM landscape.
DeepSeek-VL2
DeepSeek-VL2 is an open-source VLM with 4.5 billion parameters, developed by the startup DeepSeek. Its architecture features a Mixture of Experts (MoE) LLM, a vision encoder, and a vision-language adapter. To accommodate different needs, smaller variants with 1 billion and 2.8 billion parameters are also available.
Best for: Dynamic-resolution image processing and high-efficiency visual reasoning using Mixture-of-Experts (MoE) architecture.
NVLM
NVLM is a family of multimodal models from NVIDIA, offering distinct architectures for different purposes. NVLM-D is a decoder-only model, NVLM-X uses cross-attention for more efficient processing of high-resolution images, and NVLM-H is a hybrid that balances computational efficiency with advanced reasoning capabilities.
Best for: High-quality visual reasoning and maintaining strong text-only performance alongside leading OCR capabilities.
Qwen 2.5-VL
Developed by Alibaba Cloud, Qwen 2.5-VL is a flagship vision language model available in multiple parameter sizes (3B, 7B, and 72B). It is notable for its ability to understand long-form video content (over an hour) and to navigate desktop and smartphone user interfaces.
Best for: Understanding long-duration videos and complex, multi-page document analysis with precise object grounding.
Gemini 2.0 Flash
Part of the Google Gemini suite, Gemini 2.0 Flash is a multimodal model that can accept audio, image, text, and video as inputs.
Best for: Real-time multimodal interactions and low-latency applications requiring high-speed processing of audio, video, and text.
Llama 3.2
The Llama 3.2 family from Meta includes two open-source VLM models with 11 billion and 90 billion parameters. These models accept a combination of text and images as input and produce text-only output.
Best for: On-device (edge) deployment and efficient integration into open-source visual assistant workflows.
Challenges and Considerations
Despite their significant advancements, VLMs face several challenges and limitations that require consideration.
- Bias: VLMs can inherit and amplify biases present in their training data, reflecting socio-cultural biases or memorize incorrect patterns rather than truly understand differences in images.
- Hallucinations: Models can sometimes confidently generate incorrect, nonsensical, or factually inaccurate answers when they are unsure, a phenomenon known as "hallucination".
- Cost and Complexity: Combining vision and language models increases their overall complexity. This makes them harder to build and deploy, requiring substantial computational resources for both training and operation.
- Limited Reasoning Capabilities: VLMs rely primarily on pattern recognition rather than genuine reasoning, which limits their ability to grasp nuanced relationships between text and visuals.
- Generalization: A model's ability to adapt and make accurate predictions on new, unseen data can be a challenge. VLMs may struggle with data that is significantly different from what they were trained on.
- Privacy and Ethical Concerns: VLMs are trained on vast datasets that may contain sensitive or unconsented data, raising significant privacy and ethical challenges. Organizations must implement protective measures like data filtering and federated learning to comply with regulations such as GDPR.
Conclusion
Vision Language Models represent a fundamental shift in AI development, moving from fragmented, single-modality systems to unified architectures that process both visual and textual information. For organizations in manufacturing, finance, and other data-rich industries, VLMs unlock new capabilities in automated quality control, intelligent document processing, and enhanced visual search applications. This convergence eliminates the need for separate computer vision and NLP systems. It reduces integration complexity and opens possibilities for new applications, from real-time defect detection with natural language reporting to multimodal customer service.




